
Introducing the Weyl Gen AI API: NVFP4 Diffusion Inference with Breakthrough Efficiency

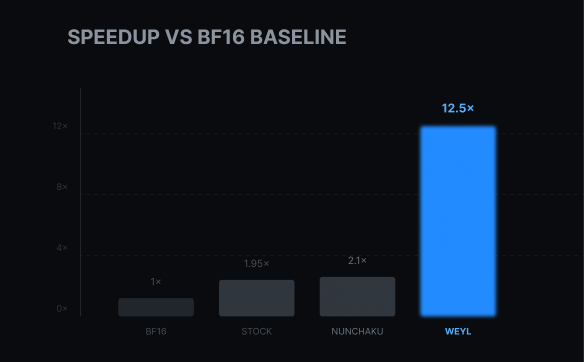
Today we're excited to announce the Weyl AI content generation API, and opening up early access to the v0 API for those interested in testing it. After months of building quietly, we're ready to start sharing what we've been working on: a no compromise approach to diffusion inference leveraging NVFP4 that delivers economically transformative efficiency for AI content generation. This blog will walk through the v0 API capabilities, our technical approach and roadmap that makes it possible, and how you can get early access.

Wait, what? How did Fleek just demonstrate better efficiency than the big AI labs?
To be honest, it kind of happened by accident. We built a first version of our product on Fal.ai and quickly realized it was way too expensive for most apps and use cases. The reality is most AI startups won't survive because current GPU and inference costs are not sustainable (see here). The big AI labs can subsidize their apps (Grok Imagine, OpenAI Sora, Meta Vibes, etc.), but for the rest of us building apps with their APIs, or using other Gen AI API providers like Fal, it's far too expensive and none of us really stand a chance.
Given the circumstances, a few months ago we decided to do some research and try building something that would allow us to compete. What we realized is that in the AI hype cycle of the last few years, it's possible several important technical considerations might have been overlooked and/or deprioritized. So we built a diffusion inference stack from scratch using first principles, and prioritized technical choices over financial resources. Here's how we did it:
- Bet the farm on NVIDIA NVFP4 & SM120 (exploring SM100 & SM110 too)
- Master our software builds as an existential priority (NixOS)
- Build specific for NVIDIA Blackwell (one of first fully leveraging it for diffusion inference)
- Make quantization a first-order priority in our engineering
- Use NVIDIA TensorRT & ModelOpt instead of TorchInductor (all-in on NVIDIA software)
- Prioritize unmanaged languages talking directly to NVIDIA silicon (C++ & CUDA)
The result: diffusion inference that is 70-80% less expensive, without sacrificing on speed or quality. We're essentially proving that NVIDIA's newest technologies can democratize AI when used correctly.

Costs That Level The Playing Field
Initial pricing for the Gen AI API will start at $0.001 per 480p image, and $0.005 per second of 480p video, with additional options for higher resolution, video length, and service tiers (ex. fast lane). Our goal is to always remain the most affordable provider with no sacrifices. This isn't VC-subsidized pricing, these are actual sustainable prices because our actual generation costs are that low.

We achieve these breakthrough costs due to a combination of things, including:
- Prosumer NVIDIA GPUs like RTX 6000s & 5090s deliver incredible price to performance and energy efficiency versus datacenter cards (ex. H100s)
- Custom NVIDIA inference stack that keeps cards at 90%+ utilization vs. much lower historical industry standard utilization rates
- Leveraging idle GPUs on platforms like Vast.ai allows zero friction, cost efficient scaling without huge upfront capital requirements, and lets us tap into unused globally distributed GPUs at costs significantly lower than traditional GPU rental or ownership
We're also working on dynamic pricing and routing for the API that automatically selects the optimal GPUs for every scenario - B200s for massive batches, RTX cards for standard workloads, edge devices when latency matters, etc.
Choices That Dominate Resources
We’re taking a hypermodern approach to AI, where technical choices are more important than financial resources. Those choices include using the absolute bleeding edge of what's available, such as NVIDIA's NVFP4, Blackwell's SM120, TensorRT, etc., as well as treating the GPUs how they want to be treated.
We don't force GPUs through abstraction layers. We are writing persistent CUDA kernels that launch once and process continuously (inspiration from the ThunderKittens). We take great care in compiling specifically for each NVIDIA compute capability. Because when you respect the hardware instead of fighting it, everything changes - 90% less compute, 90% less energy, and 90% less cost, without sacrificing speed or quality.

Our goal is to help make AI generation actually viable. While the industry burns through trillions subsidizing unsustainable inference costs, we're helping prove there's another way. And we aren’t the only ones starting to understand this. NVIDIA definitely knows about this with their recent Deepseek NVFP4 paper, groups like the one behind SageAttention3 get it, Decart is also doing great things in this direction, as well as the Nunchaku team behind SVDQuant. We're just one of the early teams putting all of the pieces of this new NVIDIA computing stack together.
The result? AI generation that's finally sustainable, even if the current AI bubble bursts.
Early Access to the v0 API
Starting today, you can request access to the Weyl Gen AI v0 API here. Weyl is the brand we will use going forward for the API product. Fleek will remain the consumer focused brand, while Weyl focuses on the API & AI infra. Similar to OpenAI/Sora, xAI/Grok, Meta/Vibes, now we will have Weyl/Fleek. The v0 API will include support for both image and video, and support the following models:
- Wan 2.2 and all variants
- Flux 1 Dev
- Flux 1 Schnell
- Qwen Image / Qwen Image Edit
- SDXL
We plan to add more models in the coming weeks, as well as expand beyond image and video into voice, 3D, and other modalities. What you're seeing is just the beginning - we're at 5% of our technical roadmap.
While our focus for now is open source diffusion models, these same efficiency advantages apply to all transformer models including LLMs. So if you're interested in exploring our tech, reach out - we'd be happy to discuss.
Request Access to the v0 API
Reach out for Business & Partnership Inquiries.
Let's democratize AI and build dope things together.
Back to the garage.


